Progressive Testing¶
Progressive testing is the discipline of building confidence in a robot step by step instead of betting everything on a hardware run. The core idea: prove behavior in cheap environments first, and only spend real hardware time on failures you couldn't have caught earlier.
1. Why Robotics Testing Has To Be Layered¶
Robotics adds sensors, actuators, timing, noisy data, and hardware you can break. If your first serious test is on the robot itself, you are learning too slowly and too expensively.
That's why teams test in layers, moving from cheap and repeatable environments toward expensive and realistic ones. Most bugs should die before they reach hardware. No single layer does every job: SIL will never tell you everything about the real world, and the robot is never the cheapest place to find a logic bug.
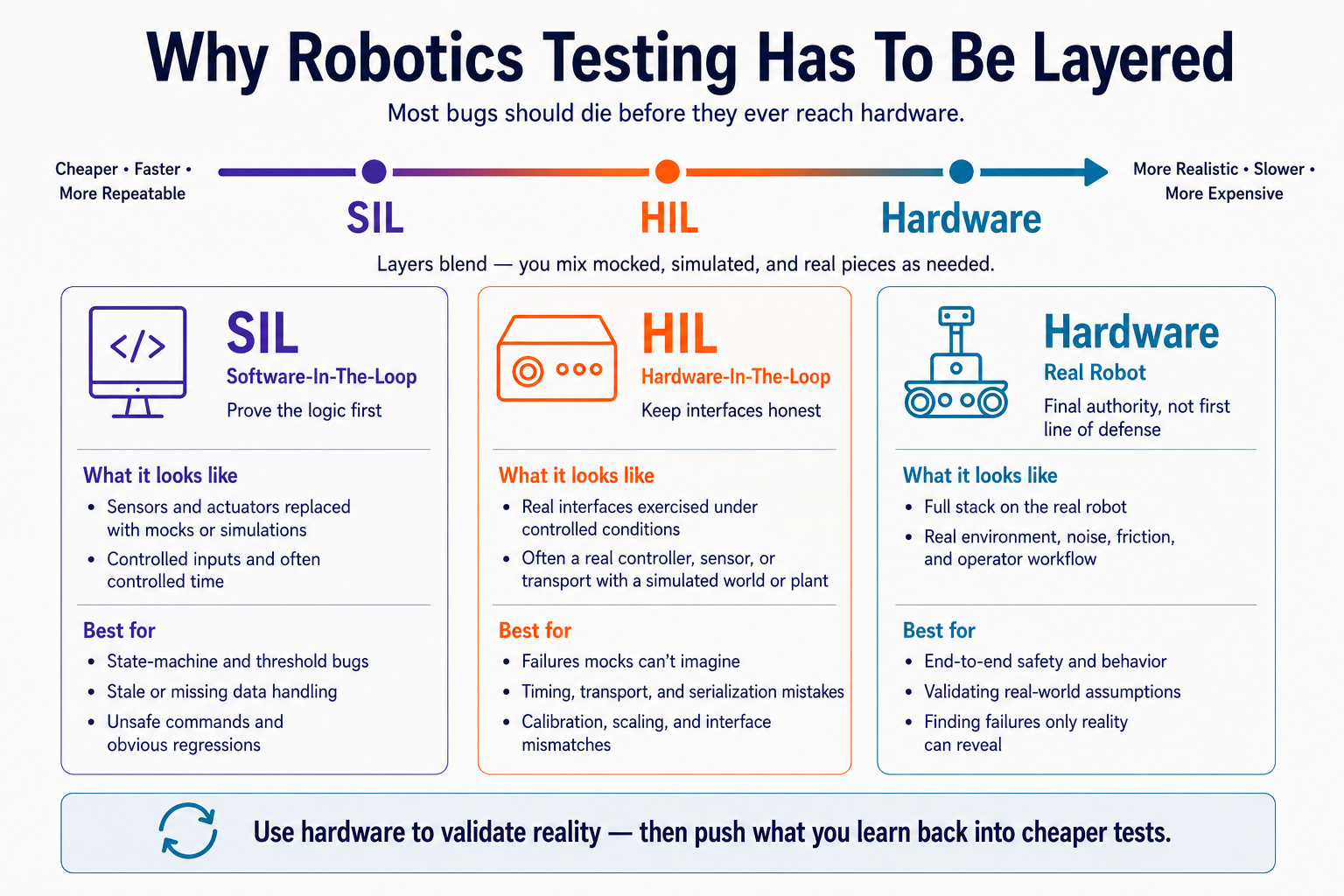
2. Software-In-The-Loop: Prove The Logic First¶
In software-in-the-loop, the robot is mostly replaced with code. Sensors are mocked or simulated, actuators are replaced with fakes, and time is often controlled by the test harness.
This is where you should catch:
- incorrect state-machine transitions
- bad threshold logic
- failure to handle stale or missing data
- unsafe command generation
- obvious planner or controller regressions
SIL is fast, repeatable, and easy to run in CI. It is the best place to test behavior that does not depend on real hardware effects.
The architectural lesson is the same one that shows up everywhere else in robotics: keep the decision-making core separated from the hardware boundary. If your logic can only run when a real camera, serial port, or motor driver is attached, you made it harder to test than it needed to be.
3. Hardware-In-The-Loop: Keep The Interfaces Honest¶
In hardware-in-the-loop, some part of the real hardware path comes back into the loop. Maybe the controller is real but the world is simulated. Maybe the sensor is real but the plant is not. Maybe the software uses the real transport stack while the test harness injects controlled inputs.
This layer exists because mocks are liars in a very specific way: they only behave how you imagined the interface would behave.
HIL is where you catch:
- timing assumptions that were invisible in unit tests
- transport or serialization mistakes
- bad calibration or scaling assumptions
- interface mismatches between software and devices
- control behavior that looks fine in logic tests but breaks under real update timing
HIL should be smaller and more selective than SIL. You are not repeating every software test. You are checking the assumptions that only become visible once a real interface is involved.
Here's a concrete failure mode that HIL exists to catch. Picture the satellite from the C++ CLI tooling assignment with two redundant temperature sensors, averaged each step, with a fault flag if the average exceeds 80 °C. A reasonable first pass at the monitor:
class ThermalMonitor:
def __init__(self, a, b, max_c=80.0):
self.a, self.b, self.max_c = a, b, max_c
self.state = "NOMINAL"
def tick(self):
avg = (self.a.read() + self.b.read()) / 2
if avg > self.max_c:
self.state = "THERMAL_SAFE_MODE"
else:
self.state = "NOMINAL"
The SIL test passes — feed it two healthy sensors, average is fine, state is NOMINAL. Ship it. Then on the bench, sensor A's driver hits a known failure mode where the device stops responding and the driver silently returns its last cached reading instead of raising an error. The monitor's trace from the HIL run looks like this:
t=0.0s A=42.1 B=43.0 avg=42.6 state=NOMINAL
t=1.0s A=42.1 B=58.7 avg=50.4 state=NOMINAL <-- A is frozen
t=2.0s A=42.1 B=74.4 avg=58.3 state=NOMINAL
t=3.0s A=42.1 B=91.2 avg=66.7 state=NOMINAL <-- satellite is cooked
The average never crosses 80 °C because the dead sensor is dragging it down. Two redundant sensors, and the redundancy made things worse — it masked the failure instead of catching it. The SIL test was right about the code it tested; it just tested the wrong code. The fake sensor never froze the way real ones do, so the failure mode the monitor needed to handle was invisible until hardware.
Reproduce the bug, then fix it
The companion Colab notebook walks through reproducing this run, diagnosing it from the trace, and fixing the monitor to check each sensor's freshness before averaging. There's a stubbed-out tick() for you to fill in, and a new SIL test that would have caught the bug from day one — once you know a failure mode exists in the real world, the cheapest place to catch it forever is back in software.
4. Hardware Tests Are The Final Authority, Not The First Line Of Defense¶
Real hardware testing matters because the real world always wins. Friction is wrong, lighting changes, sensors drift, connectors wiggle, and the environment does not care what your mocks said.
But hardware is the most expensive place to debug. It is slow to set up, hard to reproduce, and the wrong place to find basic logic bugs for the first time.
Hardware tests should answer questions like:
- does the full system behave safely in the real environment?
- do latency, vibration, lighting, or noise break our assumptions?
- do the operator workflow and failure modes still make sense on the actual platform?
If a bug could have been found in SIL, finding it on the robot is not proof of realism. It is proof that the earlier layers were too weak.
5. Don't Let Hardware Patches Poison The Core¶
The earlier HIL example showed the test half of the discipline: when hardware reveals a failure mode, roll that mode back into your SIL suite so you catch it for free from then on. This section is about the fix half: where in the code the patch lives decides whether the codebase survives. Real platforms come with quirks: a sensor that needs a 50 ms warmup after init(), a firmware bug that returns -127 once every few thousand reads, a serial port that drops the first byte after a reconnect. Each gets discovered the hard way during HIL or bench testing, usually under pressure.
The tempting move is to patch the bug where it surfaced. If the monitor saw a bad reading, fix the monitor. A week of that and the clean SIL-tested logic from earlier in this lesson looks like:
class ThermalMonitor:
def tick(self):
# Sensor A: warmup or first reads are garbage (issue #847)
if not self.warmed and time.time() - self.boot < 0.05:
return
self.warmed = True
a = self.a.read()
b = self.b.read()
# Sensor B firmware drops -127 occasionally — vendor fix "next quarter"
if b == -127:
b = self.last_b
self.last_b = b
# Hardware rev B has a slower ADC; widen the freshness window
budget = 0.2 if self.rev == "B" else 0.1
...
Every patch is locally justified. Together they have eaten the architecture. The monitor now knows what hardware revision it is on, which sensor has which firmware bug, and how long a specific ADC takes to settle. Swapping a sensor, running this code in SIL, or porting it to a new platform all just got harder. Worse, the SIL test still passes. It doesn't know about any of these conditions either, so the safety net you built has quietly stopped covering the code that actually ships.
The fix is the same boundary discipline that system design and thin shell, fat core already argued for: give each sensor a thin adapter whose only job is to present a clean .read() to the rest of the code and absorb the device's quirks behind it.
class SensorA:
"""Adapter: absorbs the 50 ms post-init warmup."""
def read(self):
if not self.warm:
time.sleep(0.05)
self.warm = True
return self._device.read()
class SensorB:
"""Adapter: hides the firmware's -127 glitch by holding the last valid reading."""
def read(self):
v = self._device.read()
if v == -127:
return self.last_valid
self.last_valid = v
return v
With every quirk now hidden behind a .read(), the monitor returns to the version from earlier in this lesson:
class ThermalMonitor:
def tick(self):
avg = (self.a.read() + self.b.read()) / 2
if avg > self.max_c:
self.state = "THERMAL_SAFE_MODE"
else:
self.state = "NOMINAL"
Its SIL test doesn't change either — the fakes that stood in for self.a and self.b are still simple objects with a .read() method. And now that we know -127 glitches and warmup delays are real failure modes, a new fake sensor can simulate them, so those bugs are catchable in software from here forward. The patches still exist, but they live at the layer that actually knows about the hardware.
A rule of thumb: if a fix mentions a hardware revision, a firmware version, a vendor ticket, or a specific serial number, it does not belong in the planner, the controller, or the monitor. It belongs at the interface, behind a name that says what it is.
Defend the adapters with SIL
The companion Colab notebook takes the adapter pattern from this section as given and asks you to build the half this page doesn't show — the SIL fakes that mimic the real hardware failure modes (-127 glitches mid-stream, garbage on first read) and the assertions that prove each adapter strips them. By the end you've turned two bench-only failures into two tests you can re-run locally — no hardware required.